Vertaalbureau MOTTE werd opgericht in 1997. Translation Agency MOTTE is founded in 1997. Le bureau de traductions MOTTE est fondé en 1997. Das Übersetzungsbüro MOTTE wurde 1997 gegründet.
Some people claim they translate tens of thousands of words per day, thanks to the use of AI.
But how strong are those claims actually?
I don’t mean those people are lying. I mean “What do they actually call a translation?”
Recently I got a telling example of a job I did myself: 166 000 words in two days! I’m not kidding you. It means I did over 83 000 words PER DAY.
But here’s the thing: it were only 9 500 words to be checked, of course spread over several sentences (or translation units, as we call that in the translation business). In those source sentences words originally written in caps were replaced by tags. The only thing I had to do, was replacing the words in the translation by those tags.
That means the 166 000 words had already been translated. Only some of them had to be replaced.
I needed 2 days for that job, which means I did almost 5000 words per day. The tricky part was the tags had to end up in the right position and they had to fit in the grammatical structure. Because of that, the translation sometimes had to be rephrased.
It shows that claims of tens of thousands of words translated per day don’t tell us anything if we don’t get a detailed analyses of the work. How much if the original words have to be translated? How much can be skipped entirely? How many translation units only demand a partial translation or retranslation?
We have to be careful to take bold claims about huge translation outputs at face value, because anyhow, a human translator is not able to do much more than 2500 or 3000 words per day from scratch, with or without AI, or MT as we call it in the translation business.
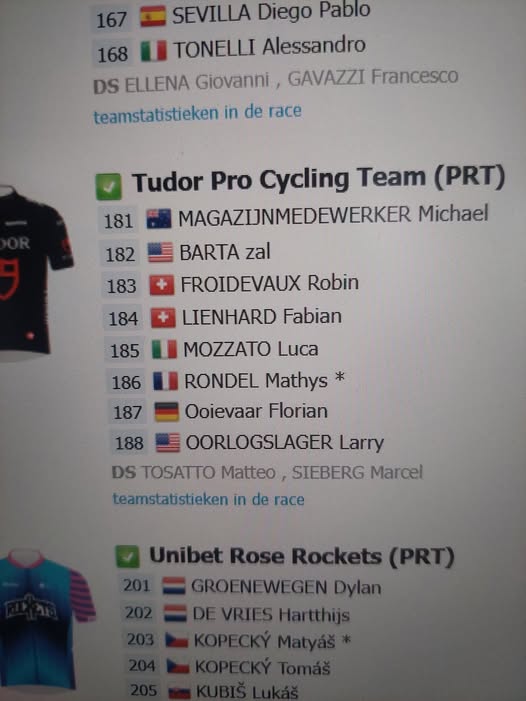
Het Tudor Pro Cycling Team (PRT) lijkt volgens een website enkele nieuwe leden te tellen, het gevolg van een AI-vertaling zonder controle. Om dat soort vergissingen te vermijden is er AI review nodig: iemand moet de vertaling nakijken.
Dat is op zich niets nieuws. Tot nu toe noemden we AI review gewoon MTPE: machine translation, post-editing. Machine translation of machinevertaling is de term die in de vertaalsector wordt gebruikt voor automatisch vertalen, een techniek die zich al meer dan tien jaar geleidelijk ontwikkelt, en net als AI steunt op enorme voorraden tekst.
In het geval van MT worden echter geen willekeurige bronnen gebruikt, maar vertalingen die al werden gemaakt voor een bepaalde klant. De nauwkeurigheid is dan ook groter dan als met gewone AI, zoals ChatGPT of Claude, wordt gewerkt, omdat alles op de eindklant is gericht. Die MT wordt geleidelijk ook bijgewerkt door intelligentere softwareroutines in te voeren. MT is dus niet vertalen met AI avant la lettre, maar de echte vorm van vertalen met AI.
Die jarenlange ervaring met MT heeft snel doen inzien dat nakijken door een menselijke vertaler, post-editing, onontbeerlijk is. En dat is precies de fout die velen maken als het om AI zelf gaat: ze gooien een tekst in een gratis tool die ze op internet hebben gevonden, of ze nemen de goedkoopste versie van een of andere aanbieder die beweert alles met AI te kunnen klaarspelen, en het nakijken laten ze achterwege. Het wordt AI zonder review.
Het resultaat wordt dan iets zoals op de foto: Michael Storer wordt Michael Magazijnmedewerker, Will Barta wordt Zal Barta, Florian Stork wordt Florian Ooievaar (note bene een Duitser) en Larry Warbasse wordt zelfs Larry Oorlogslager.
Sommigen vragen zich af waarom de Umwelt van bv. een hond nog niet geëvolueerd is tot het nabootsen van de menselijke stem. En zij besluiten daaruit dat er geen genetische behoefte voor een hond is om iets terug te zeggen. Maar de hond is nog maar een paar tienduizend jaar of zo gedomesticeerd. In zo’n korte tijd kun je niet van een “wolventaal” naar een “mensentaal” evolueren. En soms proberen honden wel degelijk met mensen te communiceren, maar het is een soort die behalve klank ook lichaamstaal gebruikt. Hij kan zich bv. tussen twee mensen wringen om ze uit elkaar te houden. Meestal is dat uit een vorm van jaloezie. Of hij kan zijn kop op je been leggen, en zeer hard drukken. Dat is vragen om eten te krijgen. Daarin zien we eigenlijk al een evolutionair element, want normaliter doen alleen welpjes dat bij de moeder om op de tepels te duwen. Volwassen honden doen dat echter ook. Dat gedrag is dus afgeleid van een ander gedrag, maar heeft een enigszins andere inhoud gekregen.
Voor sommigen is lichaamstaal echter alleen maar gedrag en geen taal. Dan beland je bij de discussie van wat je een “taal” kunt noemen. Sommigen vinden dat grammatica een voorwaarde is. Feit is dat honden van alles uitdrukken met geluid (grommen, blaffen, janken…) maar ook vaak gedrag vertonen (kwispelstaarten, door hun poten zakken, tegen je aanleunen…). Het blijft hoe dan ook communicatie, en je kunt het ene niet los zien van het andere, want dan verminder je de communicatiemogelijkheden. Overigens: de reden dat veel mensen goede vertellers maar slechte schrijvers zijn, is precies dat het lichamelijke deel bij het schrijven wegvalt, en niet alleen maar dat wat aan de gesproken taal vasthangt, zoals intonatie. Kijk, nu ben ik in de val getrapt om het over lichaamstaal als taal te hebben, maar ik vind het uitsluiten van de lichaamstaal als onderdeel van de taal van de hond een typisch symptoom van het “mensen zijn superieur”-fenomeen.
Maar wanneer worden klanken begrepen als communicatie door wie de klanken hoort? Stel dat er in een apensoort nog niet echt met tekens gecommuniceerd wordt. Bij sommige apensoorten is er een kreet die waarschuwt voor een slang. De aap kan die kreet wel slaken, maar die andere apen begrijpen dat niet noodzakelijk. Bovendien gebruiken apen van dezelfde soort overal dezelfde kreet voor die slang. Als de genetische aanpassing voor communicatie plaatsvindt in één aap, dan heeft het dier er niets aan. Het ontstaan van die kreet is echter alleen maar mogelijk is als er al een aantal andere mogelijkheden zijn: zicht, geheugen, stem… Alle elementen die nodig zijn om de kreet op te wekken, te doen uitstoten, en om de link tussen de kreet en de slang te leggen – al die bouwsteentjes – moeten aanwezig zijn voor de kreet een “waarschuwingswoord” kan worden. Als die bouwsteentjes er zijn, dan zijn die ontstaan door evolutie, maar die evolutie is niet noodzakelijk het gevolg van een behoefte aan taal. Elke willekeurige aap is dan wel in staat om de volgende stap in de evolutie te zetten: het uitbrengen van een klank die een betekenis heeft en die door andere apen als een klank met die specifieke betekenis kan worden begrepen. Er wordt niet plots een sprong gemaakt van helemaal geen taal zonder mogelijkheden tot taal, naar wél een taal. En hoe ontstaat die betekenisinhoud dan? Wie zegt dat die kreet vanaf het begin de bedoeling had om de anderen te waarschuwen? Het kan ook een poging zijn geweest om de slang weg te jagen. Als de anderen dan beginnen te begrijpen dat het betekent dat iemand een slang probeert weg te jagen, dan kunnen ze daaruit ook afleiden dat ze er zelf voor moeten uitkijken, en dan kan de kreet een vaste, waarschuwende betekenis krijgen.
FOUT Het bouwterrein stond vol zwaar materieel. GOED De bouwplaats stond vol zwaar materieel.
VERKLARING
Gefopt! Beide zijn goed. Maar er is wel een verschil: bouwplaats wordt veel meer gebruikt dan bouwterrein, dus of je het ene of het andere gebruikt, hangt af van jezelf. Wil je zo veel mogelijk mensen bereiken? Kies dan voor “bouwplaats”. Wil je gewoon in je eigen taal schrijven? Dan kies je gewoon wat het eerst in je opkomt.
Het is ook mogelijk dat je op een bepaald publiek mikt, en dan moet je weten bij welke mensen welke variant het meest wordt gebruikt. In dat geval maak je voor Nederlands automatisch een onderscheid tussen Vlaams en Nederlands, maar als we de geografische verdeling van de twee termen vergelijken, zien we iets merkwaardigs. Daarvoor gebruik ik altijd de truc dat Google Search je alleen maar zoekresultaten oplevert van het domein dat je invult na “site:”. Dus met “site:be” krijg je Belgische sites, en met “site:nl” Nederlandse.
Dat levert het volgende op: site:be “bouwplaats”: 1 060 000 site:be “bouwterrein”: 49 700 site:nl “bouwplaats”: 3 470 000 site:nl “bouwterrein”: 286 000
Het opvallende is dus dat “bouwterrein” zowel in België als in Nederland de minst populaire term is. Het verschil tussen beide is zo groot, dat het zelfs niet nodig is om de percentages uit te rekenen.
Maar wat is het verschil dan? Om dat te vinden moesten we flink zoeken.
“Bouwterrein” verwijst naar het stuk grond of de onbebouwde grond die bestemd is om bebouwd te worden (met gebouwen, infrastructuur of wegen). Het gaat hier vaak om de locatie in juridische of fiscale zin. Dat blijkt uit de definitie op de website van het Centraal Bureau voor de Statistiek (https://www.cbs.nl/nl-nl/onze-diensten/methoden/begrippen/bouwterrein) Een “bouwplaats” daarentegen is de plek waar de feitelijke bouwactiviteiten plaatsvinden. Het omvat de specifieke zone die is ingericht met bouwketen, hekken, machines en materialen ten behoeve van het bouwproces. Dat blijkt uit de definities op de website van de Rijksdienst voor het Cultureel Erfgoed, ministerie van Onderwijs, Cultuur en Wetenschap (https://thesaurus.cultureelerfgoed.nl/search;query=bouwplaats). Zij schrijven op basis van E.J. Haslinghuis: “Terrein rond een in aanbouw zijnd bouwwerk, waar zich de materiaalopslag, de werkplaatsen, bouwketen e.d. bevinden.” (Haslinghuis: Bouwkundige termen, verklarend woordenboek van de westerse architectuur- en bouwhistorie)
Er is wel een term die je beter vermijdt, namelijk bouwwerf. Want een werf is een plaats waar schepen worden gebouwd of gerepareerd, en dat is dus wat anders dan een “bouwterrein”. Een “werf” ligt altijd aan een kade, en is soms zelfs een droogdok dat volstroomt als het schip (zo goed als) klaar is. “Bouwwerf” is dus synoniem met scheepswerf, en die laatste term verdient de voorkeur.
Overigens durfde een AI te schrijven: “Een bouwwerf is een terrein waarop momenteel gebouwd wordt, inclusief het gebouw dat in aanbouw is. Synoniemen zijn werf, bouwlocatie, bouwterrein, bouwplaats. Bij een bouwwerf hoort natuurlijk een bouwplaatsinrichting. Een bouwplaatsinrichting omvat het inrichten van functioneel en veilig bouwterrein.” De AI meldde dus helemaal niet dat de term ‘bouwwerf’ gewoon een fout is. Met AI is zoiets onvermijdelijk, omdat hij allemaal maar woorden bij elkaar zet die vaak bij elkaar voorkomen. Er is geen inzicht in de betekenis ervan, niet in de logica, en al helemaal niet in allerlei voorschriften. Voor een zoekresultaat dat maar even 10 keer meer energie kost dan een gewone zoekopdracht, is dat dus slecht.
Ook interessant is de term bouwlocatie, en die geeft de volgende resultaten: site:be “bouwlocatie”: 8 340 site:nl “bouwlocatie”: 126 000 De term is toegelaten, maar niet bijzonder frequent, en daardoor vooral interessant als je wat variatie in je taalgebruik wilt brengen.
De term werkterrein, ten slotte, is de plaats waar de aannemer gebruik van kan maken voor opslag van bouwstoffen en plaatsing van keten, loodsen, hulpwerken en andere hulpmiddelen, terwijl onder het “bouwterrein” moet worden verstaan het terrein waar het werk tot stand komt. Die gegevens komen uit de toelichting op de Nederlandse UAV 2012 of “Uniforme Administratieve Voorwaarden” van 2012.
My most popular message to date on LinkedIn mentioned the problem of working on AI generated translations: it is very exhausting, and the main problem is that it takes more time than the managers seem to think.
I’m not the first translator who says that an AI generated target sentence often has to be rebuild from scratch. Not only because of mistakes, but primarily because the mistakes are spread in such an odd way in the sentence, that it costs more time to stick to correcting the mistakes in the sentence, than to translate from scratch.
If you take the AI translation as a base to work from, you have to read and reread the source and compare it again and again with the target, because the content of the original can be ordered completely different in the target. If the translator wouldn’t do that, the result could be difficult to read, and wouldn’t even sound as the target language. Hence the extra work.
It’s one of the major disappointments about AI translations. I think we’ve hit the limit of gain in time that automation can give us.
Lately an agency asked me to check translations, and they wanted to pay me per “hits”.
A “hit” is a text segment that contains a number of words.
However, they can’t tell me how many words there will be per hit, nor can they tell me how many words there will be in total and how much the payment in total would be.
Not only is the rate per hit what you normally get per word, but you don’t know whether it’s for 1 word, 2, or maybe even 7 or 10.
The translator will have to judge the accuracy of some translated sentences and grade them based on how much the meaning of the source is transferred to the translation. It was for around 5000 hits, which could be anything from 5.000 to 50.000 words.
The contact person wrote me a hit “usually consist of short sentences”. So, the final result will be closer to 50.000 words than 5.000 words.
I have, of course, declined the offer, on the grounds that a) the price was too low, and b) it’s impossible to know the workload.
a) Too low, because this kind of work is usually underestimated by the managers. It takes much more time than expected once mistakes and changes crop up.
b) It’s impossible to know how much hours I would spend on it. The minimum of 5.000 words means at least 10.000 words have to be read, which is approximately 40 fully printed pages. If there is nothing to be changed, even checking whether it’s correct is going to take at least two hours. But if it turns out to be 50.000 words, and things have to be changed, it could mean at least 2 days of work. That means it’s impossible to plan such work.
If they don’t come up with a serious price per word instead of per hit, and if they don’t tell me the amount of words, this is impossible to plan. Whether you are allowed to work at your own pace or not, doesn’t matter. The pay is far too low anyway. Moreover, accepting such offers leads to unfair competition with better paying clients.
Het is al enkele decennia bon ton om te vermijden om persoonsnamen, zoals ‘bakker’, ‘advocaat’, ‘directeur’ te zoeken zonder te impliceren dat het om mannen gaat en tegelijk vrouwen uit te sluiten. In Duitsland gebruikt men daarvoor o.a. vormen zoals “StudentInnen” en “Student*innen”. Maar er is ook een slimmere manier in opkomst, vormen zoals “Studierende”.
Het is inderdaad een mogelijkheid: woorden gebruiken die geen geslacht uitdrukken. Ik heb zelf daarom vaak enkelvoudige vormen vertaald met meervoudige, omdat “zij” (mv) geen geslacht uitdrukt.
Wat de midden-hoofdletter betreft: het is niet zo ongewoon als het lijkt, want het was in de jaren 80 een veelgebruikt marketinginstrument, bv. MicroSoft, InterNet etc. Maar het was inderdaad geen normale spelling. Dat het al eens een tijd werd gebruikt, kan het aanvaardbaarder maken.
Dat die hoge middelpunt in het Frans als radicaler wordt gezien dan de haakjesvorm (étudiant(e)s) hoeft niet te verbazen. Het vereist nu eenmaal een radicaler schrijfgedrag. Je kunt je best voorstellen dat alleen iemand die erg geëngageerd is die “hogere middelpunt” gebruikt. Ik zou niet eens weten hoe ik het uit mijn toetsenbord krijg.
Overigens is het idee dat taalverandering altijd “natuurlijk” moet groeien van “onderaf” een misvatting. Er worden tamelijk veel veranderingen van bovenaf opgelegd. Ik weet dat onlangs een artikel verscheen over waarom hen/hun er zo moeilijk ingaat (was het in Neerlandia?) terwijl andere regels juist wel goed werken, maar ik merk vaak dat er taalregels zijn die van bovenaf werden opgeleg die ook ingang vonden. De verklaring voor het succes wordt vaak louter taalkundig onderzocht, maar ik denk dat er ook nog andere factoren spelen.
Het eenvoudige ei is niet alleen een alledaags voedingsmiddel, maar ook een woord dat ons een interessante blik biedt op taal en cultuur. In vier veelgesproken Europese talen (Nederlands, Frans, Engels en Duits) heeft het woord “ei” zijn eigen vorm, klank en geschiedenis.
In het Nederlands spreken we van een “ei”. Het meervoud, “eieren”, laat meteen zien dat het woord een onregelmatige vorm heeft. Deze variatie is typisch voor oudere woorden in de taal en gaat terug tot het Oudnederlands. Het meervoud is een stapelmeervoud. Dat wil zeggen dat de meervoudsvorm een opeenstapeling is van meervoudsvormen. Het oorspronkelijke meervoud van “ei” was “eier”, zoals “kind” in het meervoud “kinder” was, maar de meervoudsvorm -er was verloren gegaan, werd niet meer herkend, en daarom werd er de bekendere vorm -en aan toegevoegd, waardoor “eieren” en ook “kinderen” ontstond.
In het Frans wordt een ei “œuf” genoemd, met als meervoud “œufs”.
Het Engels gebruikt het woord “egg”, met het regelmatige meervoud “eggs”. Dit woord is kort en krachtig en heeft zijn wortels in het Oudengels “æg”, dat sterk lijkt op de Nederlandse vorm.
In het Duits tenslotte heet een ei “Ei”, met het meervoud “Eier”. Het Duits heeft dus de meervoudsvorm -er wel nog bewaard, in tegenstelling tot het Nederlands.
Deze vier woorden tonen duidelijk hoe talen verwant kunnen zijn en toch hun eigen weg gaan. Nederlands, Engels en Duits delen een gemeenschappelijke basis: het zijn Germaanse talen. Frans is een Romaanse taal, maar hoort net als de andere drie talen bij de Indo-Europese talen, zodat de verwantschappen tussen Frans en de andere drie veel verder in het verleden liggen, en moeilijker herkenbaar zijn. Bovendien wijzen schijnbare overeenkomsten niet noodzakelijk op echte overeenkomsten.
Een mooi moment waarop deze woorden samenkomen in de praktijk is Pasen. Denk aan het zoeken naar “paaseieren” in het Nederlands, “œufs de Pâques” in het Frans, “Easter eggs” in het Engels en “Ostereier “in het Duits. Hoewel de woorden verschillen, is de traditie herkenbaar: het ei als symbool van nieuw leven in de lente.
Zo laat zelfs een klein woord als “ei” zien hoe taal, geschiedenis en cultuur met elkaar verweven zijn en hoe we elkaar toch begrijpen, zelfs als we verschillende woorden gebruiken.
Peter Motte (Geraardsbergen, 31 maart 1966) is een veelzijdige Belgische vertaler, auteur en publicist die vooral actief is in de werelden van sciencefiction, fantasy en strips. Professionele Activiteiten
Vertaler & Ondernemer: Sinds 1997 runt hij Vertaalbureau Motte in Geraardsbergen, waarbij hij technisch vertaalwerk (automobiel, ICT) combineert met literair werk en vertalingen van bekende manga’s (o.a. Death Note, Bleach) voor uitgeverij Kana. Literair Werk: Naast 13 jaar redactie van het tijdschrift De Tijdlijn, schreef hij poëziebundels en stelde hij de verhalenbundel Atlas (2013) samen.
Online Aanwezigheid Peter Motte blogt over taal, literatuur en AI, en vermijdt sociale media.
“vermijdt sociale media”… Nou ja, eigenlijk is dat wel waar, maar het staat er wel nogal apodictisch.